The Modern Java Platform - 2021 Edition
Many developers were burned by the overly complex world of Java back in the early 2000s. The Gang of Four patterns and middleware / J2EE / Java EE led to ridiculous levels of alleged decoupling as is evident in this sequence diagram from an open source J2EE ecommerce system I worked on in 2002:
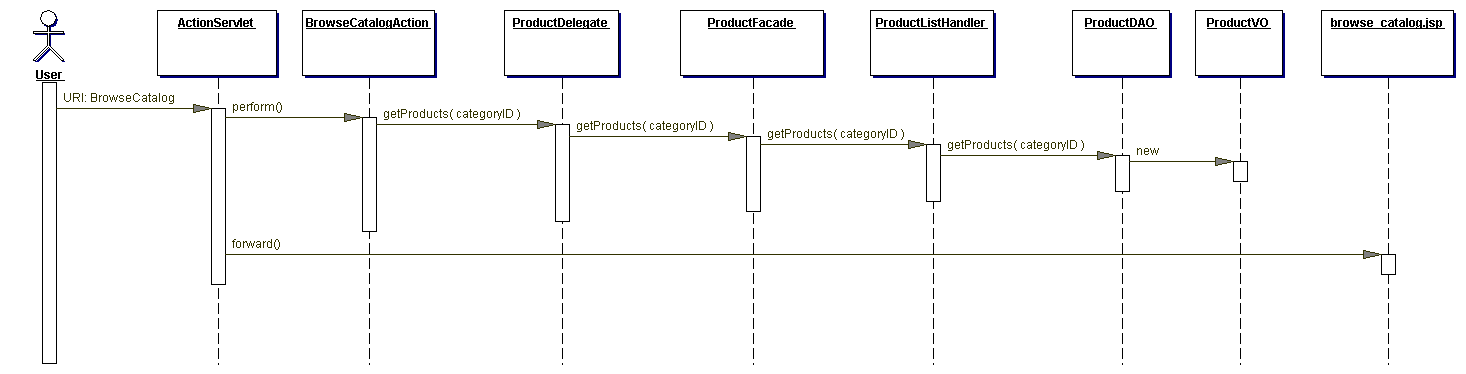
Back in 2014 I wrote about how things had changed: Java Doesn’t Suck – You’re Just Using it Wrong. But six years have passed since I wrote that and things have continued to improve, making the Java platform a fantastic option when building microservices, data pipelines, web apps, mobile apps, and more. Let’s walk through some of the “modern” (as of 2021) aspects to the Java platform.
Three Top-20 Programming Languages
Java is both a language and a platform. I honestly haven’t written much actual Java in the past decade but I’ve built quite a bit on the Java Virtual Machine (JVM). The Java language has continued to evolve; this is described by Brian Goetz (Java language architect) as “last mover advantage” - features are added after they’ve been thoroughly proved useful by other languages. For many of the millions of Java developers, the slow pace of innovation is a good thing and they are able to remain focused on reducing evolution-induced risks. Preserving backwards compatibility has long been a significant feature of the Java language for enterprises that like to move slowly and break nothing.
Aside from the Java language itself, the Java ecosystem spans other popular languages including Scala and Kotlin. In fact, most of the code I’ve written in the past decade has been in Scala, now the 14th most popular programming language (according to RedMonk). Scala has been a journey for me beginning with the “Java without semicolons” approach and now trying to fully embrace statically typed functional programming. Scala continues to try radical experiments with the upcoming Scala 3 release culminating many years of PhD research and Martin Odersky’s grand vision of basing a type system on a verifiable calculus. I really enjoy writing Scala code and the continual improvements. It feels very cutting edge and my personal productivity feels significantly better than with more archaic languages like Go.
Over the past two years I’ve written quite a bit of Kotlin code. Kotlin is now ranked #18 by RedMonk, nipping right at the heels of Go. Kotlin’s use skyrocketed when Google decided to make it the default for Android development. But I don’t do much Android programming. Kotlin has become a very productive language for building back-ends. Language features like type inference, explicit nullability, and structured concurrency (coroutines) make it great for building modern servers. When I write Kotlin I do miss some stuff in Scala but overall I’m productive and the code I write is more grokable by Java developers.
Scala and Kotlin build on the Java platform ecosystem with shared tooling, libraries, and so on. For example, Netty, a Java library, is probably the HTTP server that handles the most global traffic by type. It’s in almost every high-scale enterprise system. Many Scala and Kotlin server frameworks use Netty because the interoperability just works.
If you’ve been away from the Java language for a while and want to take another look, check out Kotlin. It has a number of modern language features and won’t feel too different. For an overview of some of the nice features check out my video: Kotlin - A Better, More Cloud-Friendly Java. If you want to take a larger jump to something even more modern, check out Scala where much of the energy lately is around writing concurrent and composable code that can be verified as correct by the compiler. I really like ZIO, a Scala framework that provides a Lego-like experience for purely functional programs.
Professional and Mature Tooling
When I use developer tooling in other platforms I’m usually disappointed. I shouldn’t need some special native library installed on my system so I can install a dependency. It shouldn’t take me hours to get my local developer toolchain set up. Code hinting in an IDE should be accurate and fast. The build system should provide standard ways to do common tasks: build, run, test, invoke static code tools, reformat the code, and other stuff we do all the time.
In the Java platform world there are a few options for build tools and IDEs. I’ve had great experiences with IntelliJ IDEA for Java, Kotlin, and Scala. But VS Code also works well. When doing Java and Kotlin, I find the Gradle or Maven build tools are mature, fast, and full-featured. In Scala I use sbt, which provides my ideal developer experience. All have direct support in IntelliJ so that my build system and my IDE have a consistent understanding of dependencies.
Applications that use databases often don’t use the production database type for dev and local integration tests because it is too painful and sometimes slow. This led many developers to use in-memory databases for dev and test. This, in turn, led to immense problems and limitations due to the differences between the dev database and the production database. Some developers have begun using Docker containers of the database dependencies to provide consistency. But this has caused pain in dealing with the lifecycle of the database. The Testcontainers project has emerged as a great way to handle this by managing the database (or other containerized service) as part of the application lifecycle. For example, integration tests can start a Postgres database for a suite of tests, or every single test case, or all tests, depending on needs - and best of all that lifecycle is managed as part of the tests themselves.
Reducing time to validate a change is essential to productivity. In my typical developer workflow I can test something I’m working on in a couple seconds. That means the compiler runs (with varying levels of validation depending on the language and framework I’m using), the tests I’m working on run, and if I’m building a web application, the server restarts and my browser auto-reloads. All of that can happen without any action on my part except for saving a file. Gradle and sbt support this out-of-the-box with a continuous build / test / dev mode. The Quarkus framework also supports this in Maven.
Check out a video of my typical developer workflow with continuous build and Testcontainers:
Productive Frameworks
In the Java ecosystem you could just write code that directly handles HTTP requests and hard-wires together the call-chain. But often a framework is used to simplify how pieces of a codebase are wired together for reuse and for different environments (dev, test, prod). There are different approaches to how that wiring happens. The most typical approach in the Java ecosystem is called Dependency Injection (DI) and was popularized by Spring Framework.
Spring Boot (the “modern” way to use Spring Framework) is the Java ecosystem framework king and works great with both Java and Kotlin. When I’m writing code with a team of non-functionally-oriented programmers, I usually use Kotlin and Spring Boot. The code is usually easy to follow and the developer experience is pretty good. There are many alternatives in this area but here are two that stand out and reasons you might want to use them:
- Micronaut - Similar programming model to Spring Boot but with a few more modern twists like compile-time Dependency Injection
- Quarkus - Java EE-based Dependency Injection with a strong focus on developer productivity
For a more complete comparison, watch my talk: Kotlin Server Framework Smackdown
With Scala, there is also a vast array of frameworks that range from Spring Boot-like to extremely functional. I’ve always been a fan of Play Framework’s developer productivity but if you want to do that style of programming, just use Kotlin. Scala really shines as you more deeply use functional programming. For this reason ZIO is my primary recommendation but there isn’t a full-blown web framework yet. There are a few libraries and basic pieces but nothing yet that matches the end-to-end framework experience of Play and Spring Boot. A solution is in the works but if you want to do pure functional with Scala for a web application today, the best option is http4s, which can be combined with ZIO.
Reactive Requests All The Way Down
Non-blocking / reactive is one of the central demarcating elements of “modern” vs traditional. Traditional systems typically use a significant amount of resources when they are just waiting for something to happen (like a database or web service to respond). This is obviously silly but fixing it usually requires new programming models because traditional imperative code doesn’t have a way to suspend and then resume when the waiting is over. Java has long had Non-Blocking IO (NIO) and most networking libraries have used it for a long time with Netty being the most commonly used. Legacy code bases may still be using blocking APIs because there is a complexity hurdle with going reactive. And until recently there weren’t mature reactive database libraries. You have to be reactive all the way down to gain enough value to outweigh the costs.
Spring Boot and most other Java and Kotlin frameworks have fully embraced reactive and made it a central part of their “modernization” story. Recently even the database tier gained great reactive support via R2DBC. However, not all ORM / data mapping libraries have support for this yet. Likewise, most HTTP client libraries support reactive programming but not all.
If you use Kotlin you can take advantage of coroutines for concurrency / reactive with Spring Boot or Micronaut. The structured concurrency model makes doing reactive almost as easy as typical imperative programming. Just make sure the libraries you are using are also non-blocking under the covers.
Reactive has been the norm in Scala for quite a while and some folks in the Scala-world created the Reactive Manifesto. As with everything in large programming communities, there are a multitude of ways you can do reactive. For an HTTP client check out sttp, which has support for ZIO. For database clients I really like Quill, which has support for various non-blocking drivers.
Reactive Event-Driven / Streaming
Aside from typical request-oriented architectures (web applications and REST services) there are also a variety of architectural patterns lumped as “event-driven” or “streaming” that have also gone reactive.
Akka’s actor-model is one framework for doing reactive / event-driven messaging. One of the core benefits of actors is supervision, which enables easy recovery when things go wrong. Akka has built-in Java and Scala support as well as a way to handle network clustered actors. On top of Akka’s actors there is a stream processing framework called “Akka Streams”, which I use in production with Scala for a real-time event processing pipeline on top of Kafka.
There are a variety of other stream processing frameworks and libraries out there including ZIO streams, Flink, ksqlDB, and Spark’s micro-batching. For many of these approaches Kafka has emerged as a typical message bus because it has great support for horizontal scaling, message replay, per topic durability settings, and at-most-once / at-least-once / effectively-once delivery.
In traditional architectures, events are processed by updating a database and then the originating event is discarded making the database the source-of-truth. In microservice architectures and distributed systems this approach is fraught with problems like eventually consistent data, inability to scale, and difficulty with adding new data processing clients. To overcome these problems newer architectural patterns have emerged including Command Query Responsibility Segregation (CQRS), Event Sourcing (ES), and Conflict-free Replicated Data Types (CRDTs).
CQRS flips the source-of-truth from the mutable datastore to the immutable event stream. This provides a much better approach for scalability, distribution, and attaching new clients / microservices. Often you still need a “materialized view” representing the state computed from processing all events. The nice thing with CQRS is you can always recompute the materialized views by replaying all the events, but in large datasets that can take a long time. Snapshots are a great way to handle this and since Kafka has the ability to replay from a given point in time, it is trivial to reconstruct materialized views from snapshots.
The biggest downside to CQRS is the programming models have been fairly low-level. Luckily ksqlDB and Cloudstate are making things much easier. I’ve used both with Kotlin and had great experiences. For more details on this approach, check out my blog about Cloudstate: Stateful serverless on Google Cloud with Cloudstate and Akka Serverless.
Containers (Not the J2EE Variety)
In the days of J2EE / Java EE we called our application servers “Containers” because they ran our web applications packaged as “Web Application aRchives” or WAR files. Today we still usually run our applications in containers but they are now polyglot, supporting many different runtimes. Popular environments for running container images include Kubernetes, Docker, and Cloud Run. There are a number of ways to create container images in the Java ecosystem including Dockerfiles, Jib, and Buildpacks. For more on the differences between these methods check out my blog: Comparing containerization methods: Buildpacks, Jib, and Dockerfile.
When creating containers you pick the “base image” that provides the operating system and the JVM. There are many different options with most being a variant of OpenJDK, the open-source reference implementation of Java Platform, Standard Edition. If you aren’t sure which JVM base image to use, you can try the pretty slimmed down Distroless Java image:
- Build:
gcr.io/distroless/java:8-debugorgcr.io/distroless/java:11-debug - Prod:
gcr.io/distroless/java:8orgcr.io/distroless/java:11
The AdoptOpenJDK builds of OpenJDK are a good choice as well but they live on DockerHub.
Some JVMs can automatically choose settings when they are running inside a container. For example, the HotSpot JVM changes the garbage collector it uses depending on the number of CPUs and amount of RAM. To reduce garbage collection pauses, the OpenJ9 JVM detects when the CPU is idle and then runs the garbage collector. OpenJDK versions released in the past few years automatically determine memory settings based on the container’s allocated RAM and have a consistent view of the CPU resources allocated to a container process.
Java, Kotlin, and Scala all run great in containers and some frameworks support out-of-the-box containerization: Spring Boot Containerization, Micronaut Containerization (Gradle | Maven), and Quarkus Containerization. Otherwise you can easily use a build tool plugin to create your container image.
Serverless and Avoiding JVM Overhead
The JVM is great at optimizing execution the more (or longer) it runs, which fits well with typical data center usage where you’ve bought the servers so you might as well keep them running even if they have low utilization some of the time. In the cloud we don’t have to do it that way. Instead we can use a model where resources are only allocated when they are being used. This is what some call “serverless” and it has the downside that servers are usually not left running for long periods of time, somewhat obviating some of the value of the JVM. Since serverless is demand-based, when a request comes in, if there aren’t enough backing resources to handle the request, a new instance needs to be spun-up. This request hits a “cold start” and they can be a real drag on your P99 latency.
Cold starts with the JVM can leave the user waiting for an uncomfortable amount of time. Imagine you click the “checkout” button on a shopping cart and nothing seems to happen for 15 seconds while the JVM starts, runtime DI annotations are processed, the server is started, caches are hydrated, and so on. One way to deal with this is to not use the JVM for JVM-based applications. What?? Seems impossible but this is exactly what GraalVM Native Image enables. It ahead-of-time compiles a JVM-based application into a native executable that starts in a tiny fraction of the time and uses less memory, but may not see “warm” performance reach the levels of a JVM-based application.
GraalVM Native Image is magic but of course there are some caveats. Ahead-of-time compilation means that some of the other magic in Java gets tricky. Many libraries in Java use runtime introspection and modification (called reflection) to dynamically handle things like Dependency Injection and serialization. These dynamic magical lurking dragons can’t be ahead-of-time compiled and so to use GraalVM Native Image you have to tell it about all of the dynamic stuff. That can be a bit tricky – possible but tricky. The major frameworks are working hard to make this easy and somewhat automatic but I’ve often run into issues.
Some Scala stuff really shines here because functional programmers don’t usually like dynamic magical dragons as they are inherently not purely functional. Once again ZIO is a great option as well as http4s. I have a GraalVM Native Imageified http4s server in production that starts in 100ms and has a 16MB container image. Because I built on some purely functional foundations, using GraalVM Native Image to ahead-of-time compile it was pretty easy.
Generally the support for GraalVM Native Image is improving and in the next few years I’m sure most modern Java, Kotlin, and Scala programs will just work without a JVM. Ahead-of-time compilation does take some time so this is something I only do in my CI/CD pipeline. I still use the JVM for local development to keep my dev and test iterations super quick.
Fear, Uncertainty, Doubt, and Governance
OpenJDK is a regular open-source project with a multi-vendor / distributed power governance structure. The Java Community Process and JDK Enhancement Proposals provide ways for anyone to contribute. Kotlin and Scala are both owned by foundations with typical open-source governance models. So in most ways, the core Java platform technologies work like other free and open programming platforms. There are, however, a few parts that are proprietary. To label a custom JDK with the Java brand (which is owned by Oracle) it must pass the tests in the Technology Compatibility Kit, which must be licensed from Oracle for such purpose. There is also a possibility that the Java language APIs are copyrightable.
With any programming platform there is risk of lock-in resulting in unexpected costs. Luckily there are some existing ways to mitigate these risks like using Kotlin or Scala along with AdoptOpenJDK.
The Future
The Java ecosystem continues to innovate in many directions. On the language side, Java, Kotlin, and Scala are all pushing in different directions but the effects are somewhat shared. For instance, Scala’s pattern matching is probably one of the best in any programming language. This has helped in some way to motivate better pattern matching in Kotlin and Java. The JVMs have also seen a ton of innovation around garbage collection and performance. Reactive programming will be even easier when Project Loom (fibers and continuations on the JVM) reaches maturity. GraalVM is an amazing piece of engineering and is helping motivate the Java community to reduce the use of dynamic magical dragons (and that is a great thing). Netty has already begun working on io_uring support (fully asynchronous Linux syscalls). Distributed data through CRDTs and CQRS is beginning to gain momentum with projects like Cloudstate. And sooo much more! There are just so many exciting things happening in the Java ecosystem!
So you’d like to modernize with the Java platform, but with such a vast ecosystem how do you know what to pick? I’d love to provide recommendations but there are so many different types of applications and many different ancillary factors that it is really hard to provide one-size-fits-all guidance. Instead here are some questions to ask:
- How deep into functional programming do you want to get?
- What technologies are your team members already familiar with?
- Do you need to run serverlessly?
- Will there be a web, mobile, or other UI sharing code with / developed by the same team as the back-end?
- What type of workload is this for? Data processing? Microservice? Web app? Other?
Let me know in the comments or via email (james at jamesward dot com) answers to these questions and I can provide some guidance.